Stephen Abrams speaks in the DCI lecture series in March 2015.
The lecture takes place at 16:00-17:30 on Thursday, March 19, in room 728 (7th floor) at the iSchool, Bissell Building, 140 St. George Street.
NOTE: We will broadcast the event on youtube: See the corresponding event page !
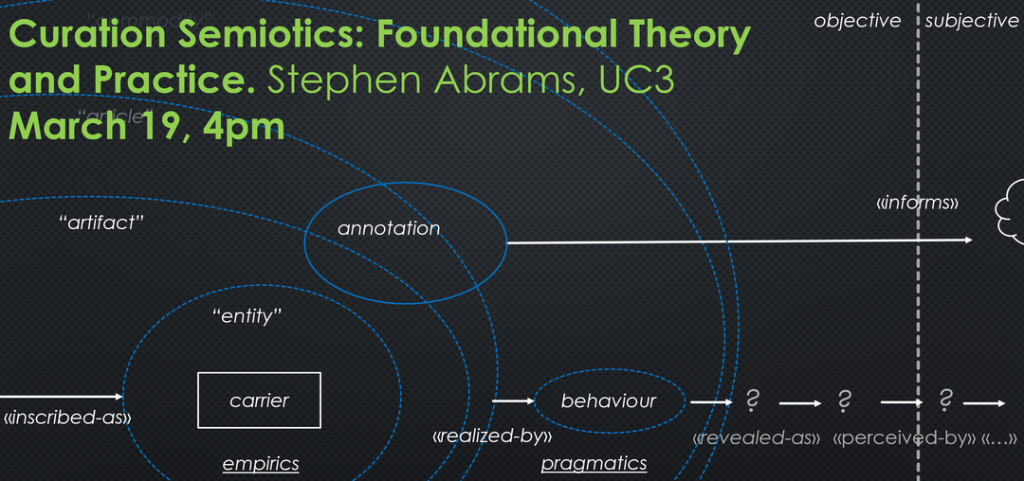
Curation Semiotics: Foundational Theory and Practice
Digital curation is a complex of actors, policies, practices, and technologies that enables meaningful consumer engagement with content of interest across space and time. The UC Curation Center (UC3) at the California Digital Library (CDL) supports a growing roster of innovative curation services for use by scholars across the 10 campus University of California system. However, recent initiatives in the area of research data curation have led to a significant change in UC3’s target audience. While UC3 continues to support its traditional campus stakeholders – librarians, archivists, and curators – it is now also engaging directly with faculty, researchers, and students.
In response, UC3 has embarked on a comprehensive review of its systems and services to ensure that it is meeting its goals most effectively. In doing so, however, a number of seemingly simple, yet deceptively difficult to answer questions cropped up almost immediately. What constitutes the full spectrum of scholarly activities for which curation support may be usefully offered? What does “preservation” mean for the new genre of research objects (or indeed, for “traditional” content)? While curation practitioners can draw upon a number of useful frameworks for specific areas of concern, for example, the Open Archival Information System (OAIS), Trusted Repositories Audit and Certification (TRAC), Preservation Metadata Implementation Strategies (PREMIS), etc., it is not clear how, or indeed whether, their underlying conceptual models cohere into a comprehensive and unified view of the curation domain. For example, many of the concepts at the heart of these standards, perhaps most problematically, “digital object”, remain woefully overloaded and under-formalized.
UC3 has developed a new model of the curation domain to provide a comprehensive, self-consistent conceptual foundation for the planning and evaluation of its activities (https://wiki.ucop.edu/display/Curation/Foundations). While drawing from many prior digital library efforts, it also incorporates relevant concepts from other disciplines. Most notably, the model considers digital content in terms of five semiotic dimensions of semantics, syntactics, empirics, pragmatics, and dynamics. This presentation will examine UC3’s role as a curation services provider within a digital age research university and the use of its domain model in decision-making processes regarding its programmatic mission, services, and initiatives.

Stephen Abrams
Biography
Stephen Abrams is the associate director of the University of California Curation Center (UC3) at the California Digital Library (CDL), with responsibility for strategic planning, innovation, and technical oversight of UC3’s services, systems, and collections, including initiatives for repositories, web archiving, data management planning, and data curation. He has participated in a leadership, governing, and advisory capacity for many digital library projects and organizations, including DataONE, Federal Agencies Digital Guidelines Initiative, International Internet Preservation Consortium, ISO 19005-1 (PDF/A), Jewish Women’s Archive, JHOVE/JHOVE2, PLANETS, and the Unified Digital Format Registry, and on conference program committees for the iPRES, IS&T Archiving, and Open Repositories conferences. His most recent work focuses on economic cost modeling for long-term sustainability of digital library services and curation domain modeling. Prior to joining the CDL in 2008, Mr. Abrams was the digital library program manager at the Harvard University Library. He holds a BA in Mathematics from Boston University and an ALM in the History of Art and Architecture from Harvard University.